Deux approches pour construire un voicebot IA : stitching versus realtime

La façon dont un voicebot IA traite la parole détermine s’il semble naturel ou lent et peu fiable. Il existe actuellement deux architectures en circulation chez les constructeurs, et le choix entre elles a des conséquences pour l’expérience d’appel, la fiabilité du système et ce que le bot peut retirer d’une conversation. L’approche ancienne enchaîne trois composants indépendants, tandis que la méthode plus récente traite toute la conversation en une seule passe.

L’approche classique : le stitching
Lorsque les premiers voicebots ont été construits, il était logique de coupler trois composants existants. La parole entrante passait par un moteur de reconnaissance vocale qui en produisait du texte, puis un modèle linguistique lisait ce texte et formulait une réponse, et enfin un moteur de synthèse vocale convertissait cette réponse en parole audible. Cette architecture s’appelle le « stitching » dans l’industrie, car vous cousez ensemble trois systèmes indépendants en une seule chaîne.
Pendant un certain temps, cette approche a livré des résultats utilisables, et pour les équipes qui ne voulaient pas entraîner un modèle vocal propre, c’était la seule route pratique. Néanmoins, trois vulnérabilités émergent en pratique, car chaque maillon peut échouer isolément. La reconnaissance vocale peut mal interpreter une phrase, le modèle linguistique peut fournir une réponse lente ou inexacte, et la synthèse vocale peut tomber en panne au mauvais moment. Beaucoup d’équipes construisent donc une sauvegarde avec un fournisseur TTS ou LLM alternatif afin que le bot continue à fonctionner en cas de panne. Cela résout la défaillance, mais les appelants entendent soudainement une voix complètement différente et s’en trouvent confus quant à l’interlocuteur.
Le deuxième inconvénient pèse peut-être encore plus lourd. Avec le stitching, le modèle linguistique ne voit qu’une transcription textuelle, ce qui signifie qu’il ne peut pas percevoir le ton, le volume, l’hésitation et l’émotion de l’appelant. Un client irrité et un client satisfait semblent identiques au modèle une fois leurs paroles mises sur papier, ce qui compromet la sensibilité contextuelle qui rend une conversation précieuse. Les signaux sur l’âge supposé, la langue maternelle ou l’humeur se perdent dans la conversion en texte, alors que ce sont précisément ces signaux qui déterminent souvent la façon dont un agent mènerait une conversation.
La nouvelle approche : un modèle vocal temps réel unique
Depuis qu’OpenAI a rendu gpt-realtime-1.5 disponible le 24 février 2026, il existe une deuxième façon de construire des voicebots qui fonctionne mieux dans la plupart des cas. Au lieu de trois composants indépendants en chaîne, un seul modèle écoute et parle directement, ce qui élimine toute la couche intermédiaire de transcription et synthèse. Le modèle comprend les paroles, le ton et l’émotion de l’appelant simultanément, de sorte qu’il peut s’adapter directement dans sa réponse. Une démo de Charlierguo montre bien l’efficacité de cette approche.
Cela produit des avantages concrets dans l’utilisation quotidienne. Il n’y a plus qu’un seul point de défaillance possible au lieu de trois, ce qui réduit considérablement le risque de panne. Le temps de réponse se situe généralement sous 400 millisecondes, de sorte que la conversation se déroule naturellement sans le délai qui se produit avec le stitching. Le multilinguisme est intégré, ce qui permet au même modèle de basculer sans effort entre le français, l’anglais, l’allemand et d’autres langues sans que vous ayez besoin de configurer ce changement à l’avance. Et parce que le modèle traite l’audio au lieu du texte, il reconnaît un client irrité à sa voix et peut le transférer directement à un agent sans avoir besoin d’un mot-clé ou d’une escalade explicite.
Quand le stitching reste le bon choix
Il reste un créneau où l’architecture ancienne s’avère meilleure : les situations où aucune conversation en direct n’est nécessaire mais plutôt une analyse d’enregistrement après coup. Lorsqu’un centre d’appels souhaite résumer, coder ou vérifier les appels après coup pour la conformité, il n’y a aucune exigence de latence et vous pouvez facilement choisir un modèle linguistique spécialisé. Pensez à un modèle médical qui reconnaît les abréviations et la terminologie technique de la santé, ou à un moteur de reconnaissance vocale entraîné spécialement sur un dialecte régional. La précision sur cet élément particulier pèse dans ces scénarios plus lourd que l’expérience conversationnelle globale, car aucun appelant n’attend une réponse en ligne.
Notre recommandation
Pour les entreprises qui souhaitent que des voicebots gèrent des conversations en direct, nous recommandons dans presque tous les cas l’approche temps réel. La combinaison de réponses plus rapides, de moins de sensibilité aux pannes, de multilinguisme sans configuration et de sensibilité au ton crée une expérience d’appel que les appelants n’expérimentent pas comme robotique. Pour les analyses post-appel et d’autres scénarios où la précision sur un composant spécifique est décisive, nous continuons à déployer des architectures stitching, car elles y livrent encore les meilleurs résultats.
Notre équipe construit dans les deux architectures
CallFactory construit des voicebots dans les deux architectures, selon ce qui convient le mieux à votre flux d’appels. Que vous désiriez une solution entièrement gérée où notre équipe met en place tout de bout en bout, ou plutôt un IVR dédié fonctionnant sur votre propre infrastructure, nous livrons des implémentations conformes au RGPD disponibles 24 heures sur 24, sept jours sur sept.
Prenez contact avec notre équipe pour discuter quelle architecture convient à vos appels, comment l’intégration avec vos systèmes existants se déroulera et dans quel délai le voicebot peut devenir opérationnel. Vous obtiendrez une estimation claire du délai de mise en œuvre et de l’investissement, et vous pourrez dès le premier jour traiter les appels entrants et sortants avec un voicebot qui parle et écoute à un niveau qui était impensable jusqu’à récemment.
Questions fréquemment posées
Le stitching reste précieux lorsque vous n’avez pas besoin de conversation en direct mais plutôt d’une analyse d’enregistrement après coup. Vous avez alors la liberté de sélectionner un modèle linguistique spécialisé, par exemple un modèle médical pour la terminologie médicale ou un moteur de reconnaissance vocale entraîné sur un dialecte régional particulier. Dans ces cas, la précision sur un seul élément prime sur une expérience conversationnelle fluide.
Le temps de réponse se situe généralement sous 400 millisecondes, ce qui correspond à une conversation téléphonique normale entre deux personnes. Comme il n’y a pas de composants distincts en chaîne, le délai qui apparaît avec le stitching disparaît complètement, si bien que les appelants remarquent rarement qu’ils parlent à une IA.
Oui. Les modèles vocaux temps réel sont entraînés de façon multilingue, ce qui leur permet de basculer entre le français, l’anglais, l’allemand et d’autres langues au cours d’une même conversation sans que vous ayez à configurer ce changement à l’avance. Pour une entreprise française ayant une clientèle internationale, cela élimine toute une étape de configuration.
Nous intégrons un itinéraire de basculement sur chaque projet, de sorte que l’appel soit automatiquement transféré à un agent ou à un message pré-enregistré en cas d’indisponibilité. L’appelant ne remarque que le transfert, ce qui signifie que votre flux d’appels continue à fonctionner même en cas d’interruption chez le fournisseur.
Oui. Nous configurons le voicebot de façon que l’audio et les métadonnées restent au sein de l’Union européenne et que tous les prestataires impliqués disposent d’un contrat de traitement des données. Pour les secteurs réglementés tels que la santé, les banques et l’assurance, nous proposons en outre une variante auto-hébergée qui s’exécute entièrement derrière votre propre pare-feu.

WhatsApp instaure les noms d'utilisateur : qu'est-ce qui change pour votre entreprise ?

Trunk SIP : Comment Ça Marche et Comment le Raccorder à Votre Standard
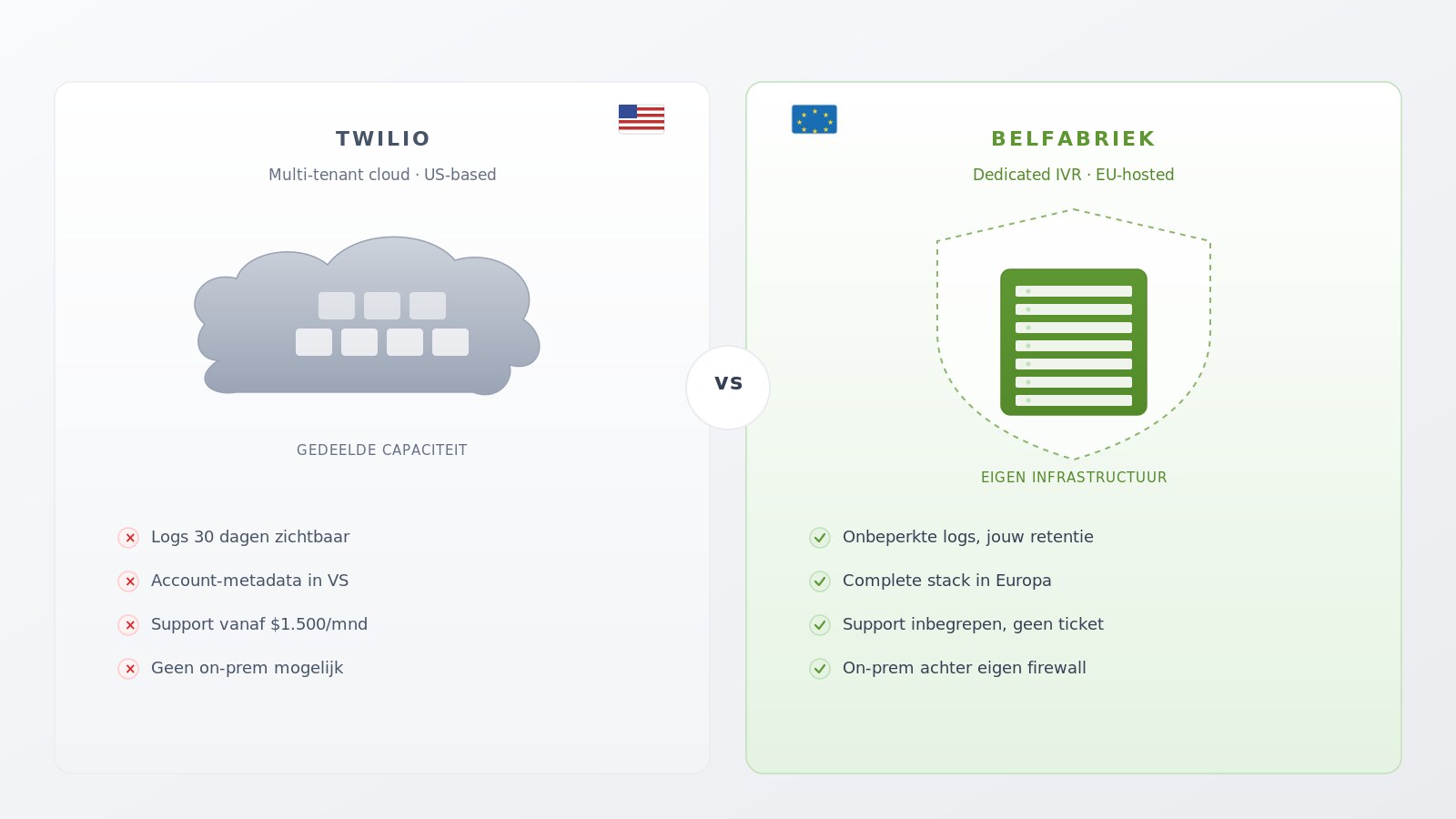
Pourquoi un serveur IVR dédié ou une API privée fonctionne plus vite que construire sur Twilio









